
Cracking the Code of Complexity | Unveiling Hidden Equations in Nature | How a New Machine-Learning Algorithm is Transforming Data into Interpretable Scientific Models
 In a groundbreaking development at the intersection of data science and physics, researchers have advanced a machine-learning algorithm that can extract the governing equations and control parameters of complex systems using only a handful of measurements. This breakthrough approach enables scientists to transform seemingly chaotic data—whether from a steaming cup of coffee or the turbulent behavior of a superconductor—into a clear mathematical narrative. By inferring key variables from minimal observations, the algorithm not only demystifies the underlying dynamics of the system but also sets a new benchmark in data-driven scientific discovery.
In a groundbreaking development at the intersection of data science and physics, researchers have advanced a machine-learning algorithm that can extract the governing equations and control parameters of complex systems using only a handful of measurements. This breakthrough approach enables scientists to transform seemingly chaotic data—whether from a steaming cup of coffee or the turbulent behavior of a superconductor—into a clear mathematical narrative. By inferring key variables from minimal observations, the algorithm not only demystifies the underlying dynamics of the system but also sets a new benchmark in data-driven scientific discovery.
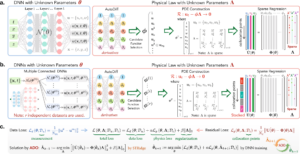
At the heart of this innovation lies a methodology that builds two extensive libraries: one composed of hundreds of potential terms that might describe a system’s behavior, and another cataloging all conceivable control parameters. The algorithm applies sparse matrix regression to these libraries, effectively filtering out extraneous terms until only the most crucial components remain. This rigorous pruning process ensures that the resulting model is both parsimonious and scientifically interpretable, offering an elegant solution to the challenge of modeling systems that defy straightforward first-principles analysis.
A notable improvement over the 2016 version of the algorithm is its enhanced ability to recognize when disparate datasets originate from the same underlying system. This is achieved through an additional training step that consolidates data from different regimes—whether the gentle rocking of a coffee surface or the chaotic splashing triggered by a brisk walk. By identifying and honing in on the critical control parameters, the algorithm can predict system behavior even under conditions where no data currently exist. Its built-in noise-mitigation strategy further refines these predictions, though the model’s accuracy remains contingent on the quality of the measurements provided.
The research team demonstrated their method with relatable examples, such as determining the fastest pace at which one can walk with a full cup of coffee without spilling it. They also applied the technique to more abstract systems like those described by the Ginzburg-Landau equation—a mathematical model that underpins phenomena in superconductivity—and oscillatory chemical reactions. These demonstrations highlight the algorithm’s versatility, showing that it can sift through vast libraries of potential terms and extract the precise ingredients that dictate system dynamics.
Beyond its immediate technical achievements, the algorithm opens up exciting new avenues for understanding systems that have long puzzled scientists. Applications range from unraveling the mysteries of turbulence in fluid dynamics to modeling the intricate behavior of neurons in the brain. The ability to infer governing equations from data has profound implications across disciplines, empowering researchers to develop more reliable models where traditional theoretical approaches have often fallen short.
Supplementing the insights provided by the original study, additional research from reputable sources emphasizes that data-driven discovery is rapidly evolving into a cornerstone of modern scientific inquiry. Institutions like the American Physical Society and the Joint Quantum Institute have been pivotal in fostering developments in this area, showcasing how machine-learning techniques can bridge the gap between abstract theory and empirical observation. This growing body of work reinforces the idea that embracing interdisciplinary approaches not only accelerates scientific progress but also broadens our understanding of the natural world.
As we look to the future, the potential of such algorithms to democratize scientific discovery is truly inspiring. By turning raw, noisy data into coherent, interpretable models, researchers like John and his colleagues at SpeciesUniverse.com are paving the way for a deeper understanding of complex phenomena. This approach challenges us to rethink the boundaries between experimental observation and theoretical modeling, suggesting that the secrets of the universe might be unlocked by the marriage of data science and classical physics.
Key Takeaways:
- Key Mechanism: The algorithm utilizes dual parameter libraries and sparse matrix regression to extract minimal yet complete models from limited data.
- Enhanced Accuracy: An additional training step allows the algorithm to recognize consistent patterns across different data regimes, improving its predictive power even in noisy environments.
- Broad Applications: This method holds promise for advancing our understanding of diverse systems, from everyday occurrences like coffee dynamics to intricate phenomena such as brain activity and turbulence.
“Using a few measurements of a pattern-forming system, a new machine-learning algorithm can determine the system’s governing equations and their parameters in a form that is interpretable by scientists.”
Ready to dive deeper into the intersection of data science and physics? Explore more groundbreaking insights and related content on SpeciesUniverse.com—join the conversation, share your thoughts, and help shape the future of scientific discovery!
More details: here
Leave a Reply